One-Shot Object Detection without Fine-Tuning
Xiang Li1* Lin Zhang1* Yau Pun Chen1 Yu-Wing Tai2 Chi-Keung Tang1
1Hong Kong University of Science and Technology
2Tencent
Model
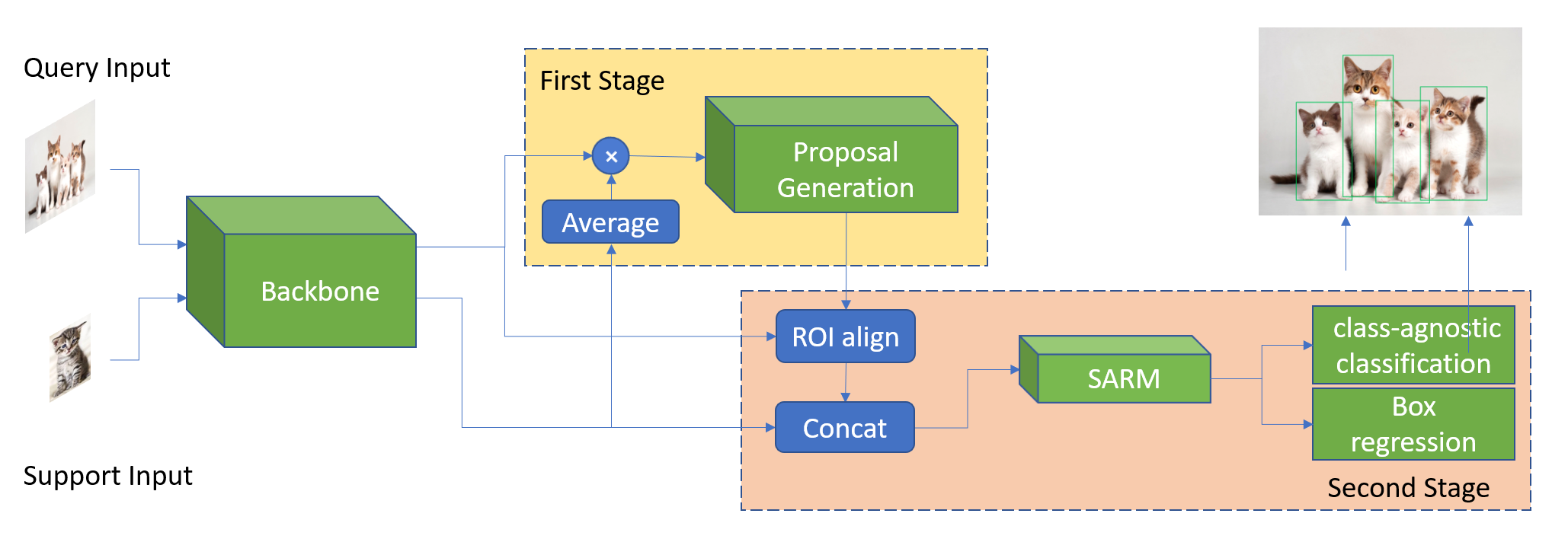
Overview of our architecture. The query and support images are first fed into a shared siamese backbone network. Then our Matching-FCOS produces a set of high-recall proposals. The second stage, which we term Structure-Aware Relation Module (SARM), learns to classify and regress bounding boxes by focusing on structure local features. The final goal is to detect objects in the query image with the same class of the support object.
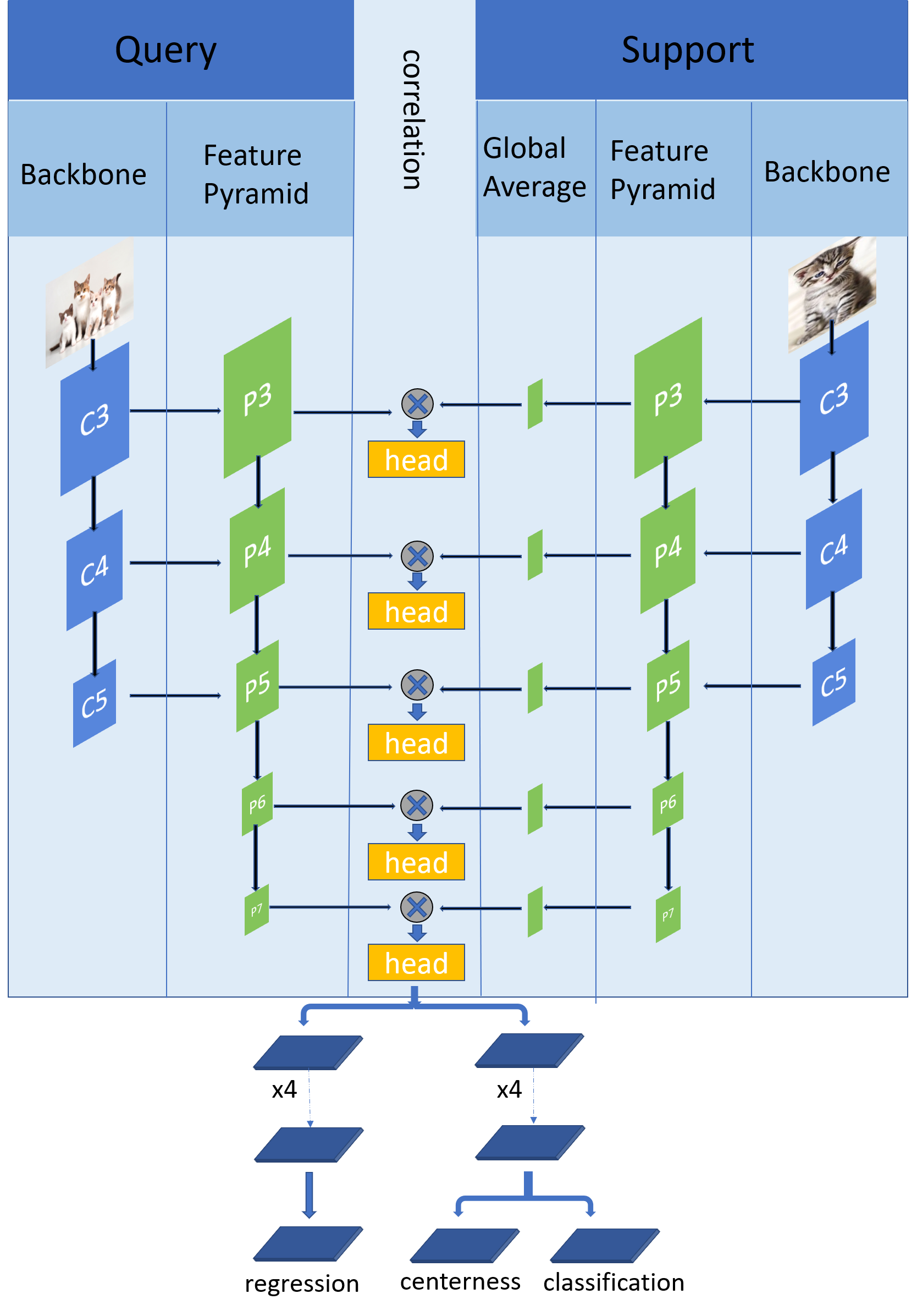
Matching-FCOS network as the first stage of our model. C3--C5 refers to feature maps of the backbone and P3--P7 refers to feature maps of the FPN.
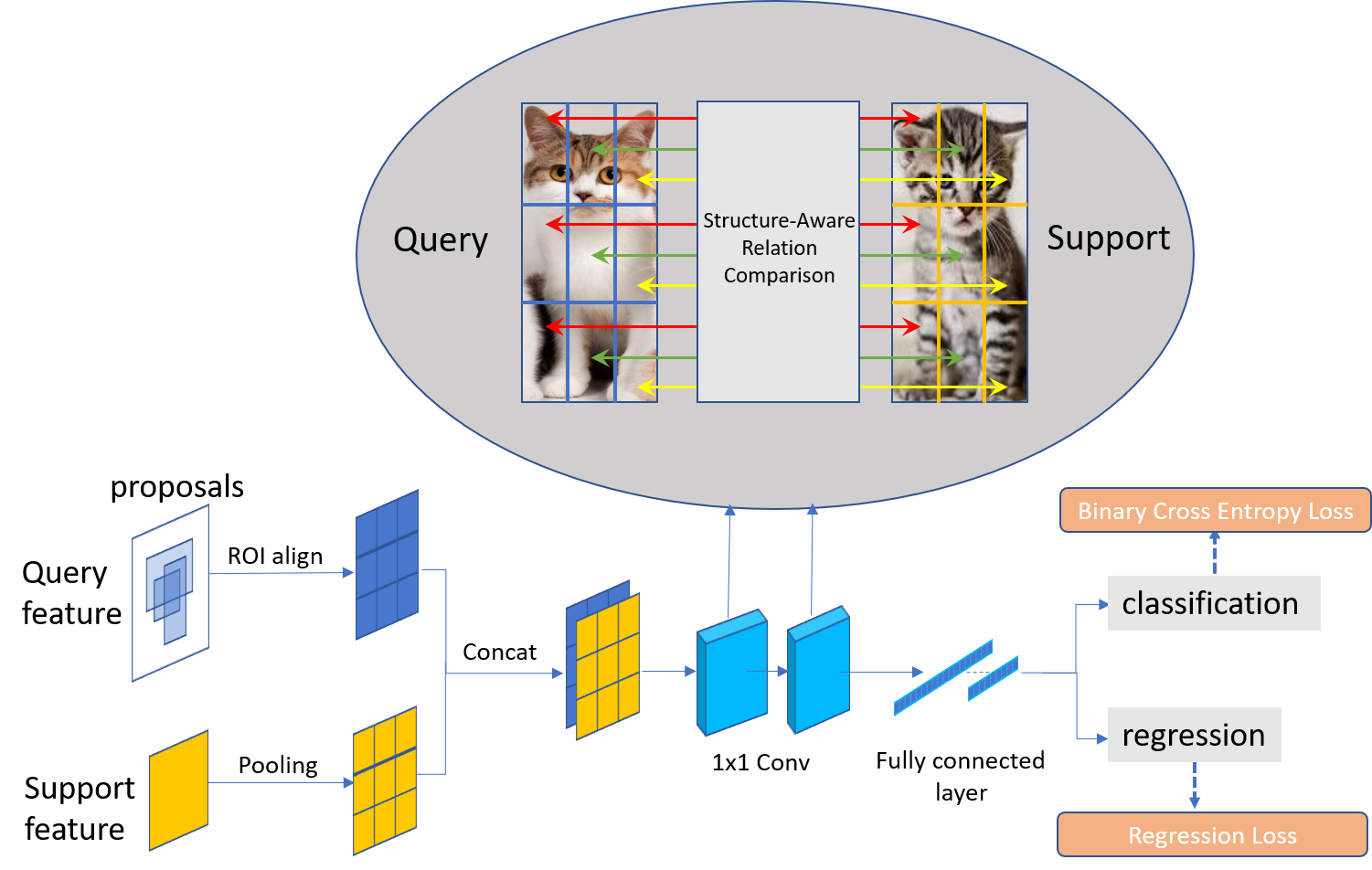
Structure-Aware Relation Module (SARM) at the second stage. We first pool query proposals features and support features into K x K features and concatenate them. We then use pixel-wise convolutional layers to compare structure-aware local features. Here, the cat is decomposed into structural modules including ears, feet, etc. By processing these features locally, our module can discover more relevant cues to achieve higher detection precision.
Performance
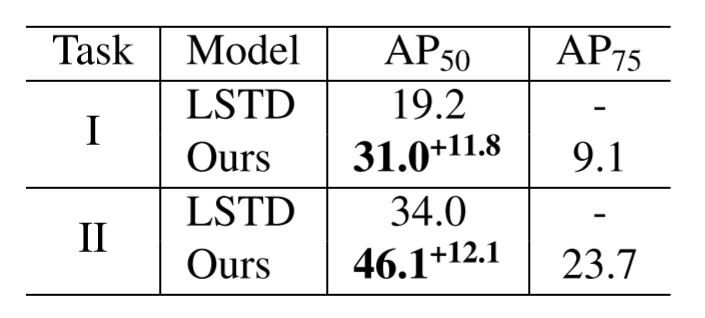

Comparison with previous work LSTD (which requires fine-tuning) in one-shot settings evaluated on task I (trained on COCO and tested on ImageNet-LOC) and II (trained on COCO excluding PASCAL VOC classes and tested on PASCAL VOC) following the LSTD paper, as well as the abalation study of our model on task II.

Per-class performance of our method on task II.
















