|
Xiang (Ryan) Li
My name is Xiang Li (李想; pronounced "Shiang Li"). I am a fifth-year Ph.D. student at the University of Illinois Urbana–Champaign (UIUC), advised by Prof. James M. Rehg. My research focuses on the analysis and alignment of visual generative AI, with an emphasis on 3D generation.
In recent years, I have interned at Meta Superintelligence Lab, working with Weiyao Wang, Sasha Sax, Hao Tang, and Matt Feiszli. I also interned at Google Research with Boqing Gong. I received my bachelor's degree from The Hong Kong University of Science and Technology (HKUST), where I was advised by Prof. Yu-Wing Tai and Prof. Chi-Keung Tang.
🚀 I am currently looking for full-time opportunities. Please feel free to reach out!
Email /
CV /
Google Scholar /
LinkedIn
|

|
|
|
SAM 3D: 3Dfy Anything in Images
SAM 3D Team
CVPR 2026 (Best Paper Honorable Mention ✨)
paper
/
project page
/
code
We present SAM 3D, a generative model for visually grounded 3D object reconstruction, predicting
geometry, texture, and layout from a single image.
Personal Contribution: Main contributor to post-training, preference optimization.
|
|
|
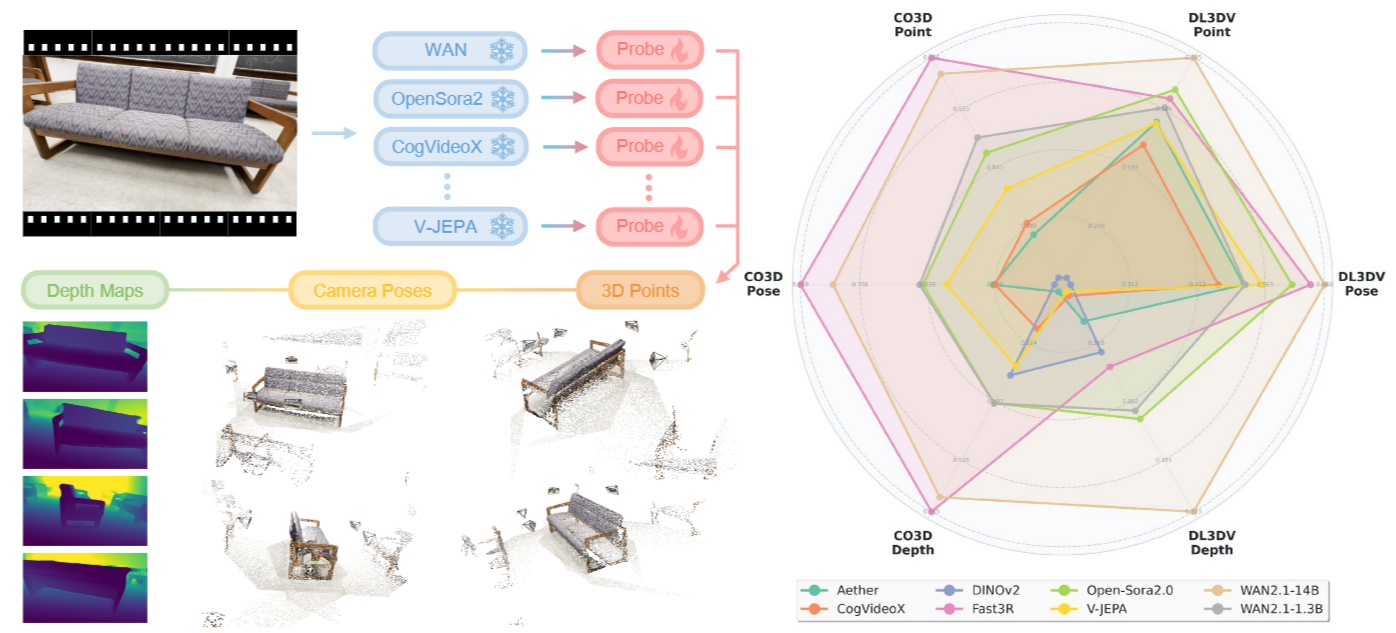
How Much 3D Do Video Foundation Models Encode?
Zixuan Huang*,
Xiang Li*,
Zhaoyang Lv,
James M. Rehg
CVPR 2026
paper
/
project page
After training on large video data, will global 3D understanding naturally emerge? We study this by quantifying the 3D understanding of existing Video Foundation Models pretrained on vast video data, by estimating multiple 3D properties from their features via shallow read-outs.
|
|
|
Vinedresser3D: Agentic Text-guided 3D Editing
Yankuan Chi*,
Xiang Li*,
Zixuan Huang,
James M. Rehg
CVPR 2026
paper
/
project page
/
code
We propose an agentic framework for text-guided 3D editing. Vinedresser3D uses a multimodal LLM to interpret editing prompts and performs precise, mask-free 3D editing directly in the latent space of a native 3D generative model.
|
|
|
Cue3D: Quantifying the Role of Image Cues in Single-Image 3D Generation
Xiang Li*,
Zirui Wang*,
Zixuan Huang,
James M. Rehg
NeurIPS 2025 (Spotlight ✨)
paper
/
project page
Which image cues do 3D generation models actually rely on? We systematically perturb monocular cues (shading, texture, silhouette, perspective, etc.) across seven state-of-the-art methods and quantify their impact on 3D generation.
|
|
|
Symmetry Strikes Back: From Single-Image Symmetry Detection to 3D Generation
Xiang Li,
Zixuan Huang,
Anh Thai,
James M. Rehg
CVPR 2025 (Highlight ✨)
paper
/
project page
/
code
Symmetry is a ubiquitous property of real-world objects, yet 3D generation models ignore this. We introduce Reflect3D, a zero-shot 3D reflection symmetry detector from a single image, and show that incorporating detected symmetry into 3D generation improves structural accuracy and visual fidelity.
|
|
|
Video State-Changing Object Segmentation
Jiangwei Yu*,
Xiang Li*,
Xinran Zhao,
Hongming Zhang,
Yu-Xiong Wang
ICCV 2023
paper
/
project page
/
dataset and code
Video object segmentation (VOS) models struggle when objects change state (e.g., an egg being cracked). We introduce the VSCOS benchmark for this underexplored setting, and propose an improved baseline for VOS of objects undergoing state changes.
|
|
|
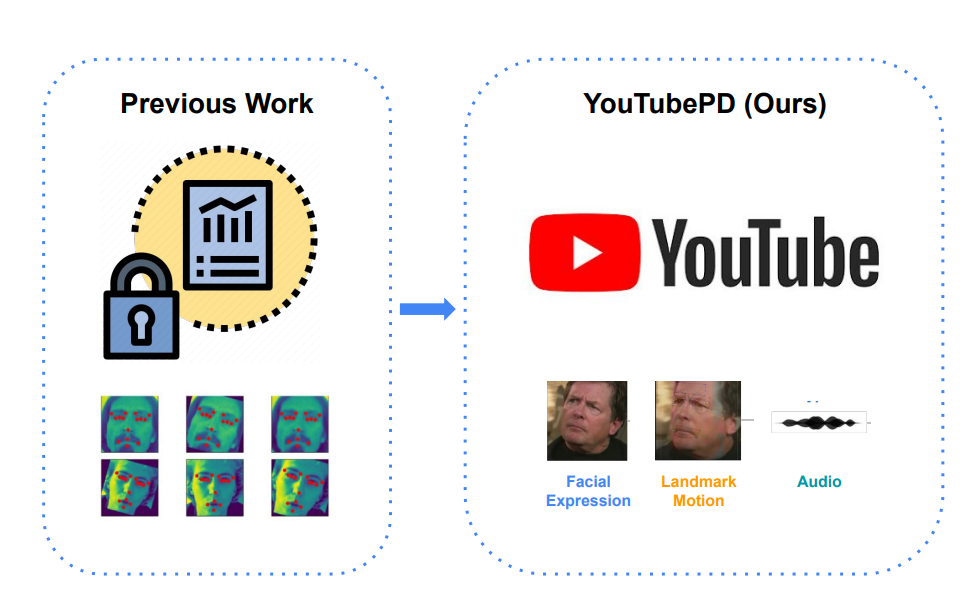
YouTubePD: A Multimodal Benchmark for Parkinson's Disease Analysis
Andy Zhou*,
Samuel Li*,
Pranav Sriram*,
Xiang Li*,
Jiahua Dong*,
Ansh Sharma,
Yuanyi Zhong,
Shirui Luo,
Maria Jaromin,
Volodymyr Kindratenko,
George Heintz,
Christopher Zallek,
Yu-Xiong Wang
NeurIPS Datasets and Benchmarks Track 2023
paper
/
project page
/
dataset
We introduce YouTubePD, the first public multimodal benchmark for Parkinson's Disease (PD) analysis, crowdsourced from existing YouTube videos featuring over 200 subjects.
|
|
|
FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation
Xiang Li,
Tianhan Wei,
Yau Pun Chen,
Yu-Wing Tai,
Chi-Keung Tang
CVPR 2020
paper
/
dataset and code
In few-shot segmentation, class diversity matters more than data quantity. We introduce FSS-1000, a 1000-class dataset with pixel-wise annotations that prioritizes breadth over depth, enabling more robust generalization and more precise evaluation.
|
|