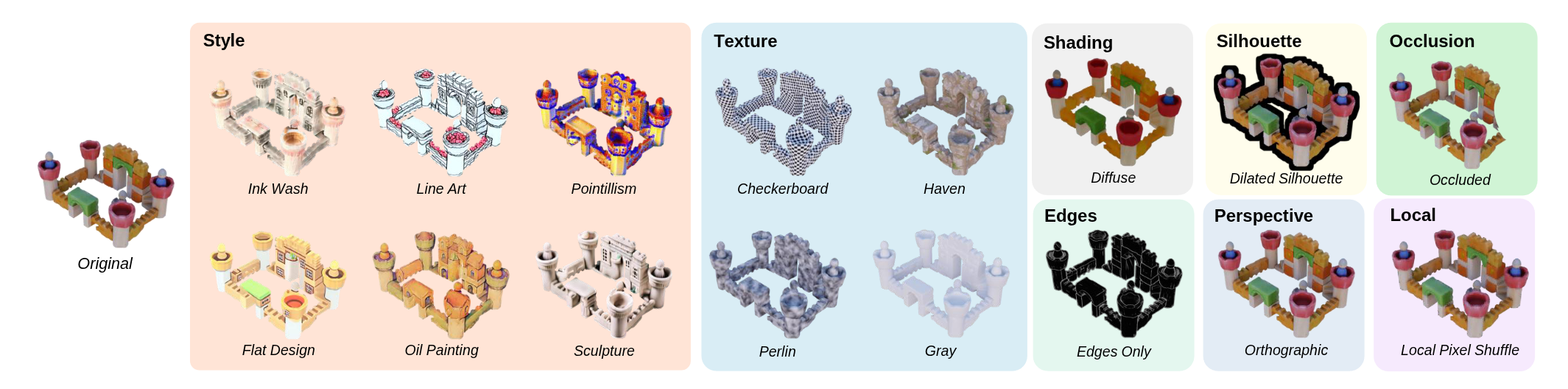
TL;DR: We introduce Cue3D, the first comprehensive, model-agnostic framework for quantifying the influence of individual image cues in single-image 3D generation. From a single input image, we disable or modify specific cues, such as silhouette shape, shading, texture semantics, perspective, and local continuity, and measure the resulting degradation in 3D output quality. We then evaluate representative methods from three paradigms: regression-based, multi-view, and native 3D generative models, and measure performance deltas to quantify cue dependence and robustness across datasets. In this way, our perturbation analysis uncovers how modern single-image 3D models leverage image cues.
Abstract
Humans and traditional computer vision methods rely on a diverse set of monocular cues to infer 3D structure from a single image, such as shading, texture, silhouette, etc. While recent deep generative models have dramatically advanced single-image 3D generation, it remains unclear which image cues these methods actually exploit.
We introduce Cue3D, the first comprehensive, model-agnostic framework for quantifying the influence of individual image cues in single-image 3D generation. Our unified benchmark evaluates seven state-of-the-art methods, spanning regression-based, multi-view, and native 3D generative paradigms. By systematically perturbing cues such as shading, texture, silhouette, perspective, edges, and local continuity, we measure their impact on 3D output quality. Our analysis reveals that shape meaningfulness, not texture, dictates generalization. Geometric cues, particularly shading, are crucial for 3D generation. We further identify over-reliance on provided silhouettes and diverse sensitivities to cues such as perspective and local continuity across model families.
By dissecting these dependencies, Cue3D advances our understanding of how modern 3D networks leverage classical vision cues, and offers directions for developing more transparent, robust, and controllable single-image 3D generation models.
(1) Meaningfulness of shape, not texture, dictates generalization. For models to generalize, the input image must indicate a meaningful shape that does not significantly deviate from the training distribution. When we disrupt this cue by providing the models with a stochastic combination of textured primitive shapes (or random CutMix of meaningful 3D assets), models on average perform poorly with distinct failure modes. In contrast, the models perform surprisingly well on meaningless or random textures, with the best-performing models showing near perfect generalization.
(2) Semantics alone are not enough; Geometric cues are crucial. Using a state-of-the-art style-transfer method, we convert images into artistic styles that preserve high-level semantics but often disrupts geometric cues like realistic shading and texture. We observe a significant drop on the performance compared to the original images, underscoring the continued importance of geometric cues.
(3) Shading is more important than texture. To dissect the contribution of different geometric cues, we dive deeper into the image formation process. Surprisingly, even when all recognizable textures are replaced by procedural noise, natural patterns, or flat gray, for several methods, the quality of the 3D outputs remain almost unchanged, as long as the shading is kept intact. However, removing shading causes a noticeable performance decline. We further discover an interplay between shading and texture cues: intact shading alone suffices to uphold performance regardless of texture content, but when shading is removed, preserving the original texture yields better results than substituting with procedural textures or uniform color.
(4) Models are overly sensitive to silhouette and occlusion. Dilating the object mask (without altering interior pixels) inflicts severe errors on regression-based and multi-view methods, whereas one native 3D generator remains relatively robust. In contrast, occlusion of both silhouette and image content dramatically degrades all approaches.
(5) Other cues have diverse impact. Perturbing perspective, edge, and local-continuity signals produce measurable performance drops that vary across model categories, which we provide thorough analysis in the experiments section.
BibTeX
@inproceedings{li2025cue3d,
author = {Li, Xiang and Wang, Zirui and Huang, Zixuan and Rehg, James M.},
title = {Cue3D: Quantifying the Role of Image Cues in Single-Image 3D Generation},
booktitle = {NeurIPS},
year = {2025}
}